Internals of YARN architecture
Overview
Apache YARN (Yet Another Resource Negotiator) is the cluster resource management layer of Hadoop. The Yarn was introduced in Hadoop 2.x.
Yarn allows different data processing engines like graph processing, interactive processing, stream processing as well as batch processing to run and process data stored in HDFS (Hadoop Distributed File System). Apart from resource management, Yarn also does job Scheduling.
Yarn extends the power of Hadoop to other evolving technologies, so they can take the advantages of HDFS (most reliable and popular storage system on the planet) and economic cluster.

YARN Daemons
1. Global Resource Manager
The main job of resource manager is to distribute resources among various applications in the system. It has two main functionalities.
Scheduler:
Pluggable component which decides allocation of resources to various running applications. Pure Scheduler does not monitor or track the status of application.
Know more about scheduler on my article on Deep dive into YARN Scheduler options
Application Manager:
- Accepts the job submissions
- Negotiating resources (containers) for executing the Application Master
- Restarting the Application Master in case of failure
The Resource Manager is responsible for handling the resources in a cluster and scheduling multiple applications. Before to Hadoop v2.4, the RM was the SPOF.
The High Availability feature adds redundancy in the form of an Active/Standby Resource Manager pair to remove this otherwise single point of failure.
Resource Manager HA is realized through an Active/Standby architecture at any point in time, one in the masters is Active, and other Resource Managers are in Standby mode, they are waiting to take over when anything happens to the Active.
The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic failover is enabled using Zookeeper.
2. Node Manager
- Per machine slave daemon
- Responsible for launching the application containers for app execution
- Monitors the resource usage such as memory, CPU, disk etc.
- Reports the usage of resources to global Resource Manager.
- All nodes of the cluster have a certain number of containers. Containers are computing units, a kind of wrappers for node resources to perform tasks of a user application. They are the main computing units that are managed by YARN. Containers have their own parameters that can be configured on-demand (e.g. ram, CPU, etc.).
3. Application Master
- Per application specific entity
- Responsible for negotiating the resources for execution from Resource Manager
- Works with Node Manager for executing and monitoring component tasks.
YARN architecture for running a Map Reduce Job
The whole process is illustrated at the highest level in below diagram, there are five independent entities:
- The client, which submits the MapReduce job.
- The YARN resource manager, which coordinates the allocation of compute resources on the cluster.
- The YARN node managers, which launch and monitor the compute containers on machines in the cluster.
- The MapReduce application master, which coordinates the tasks running the Map Reduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
- The distributed filesystem, which is used for sharing job files between the other entities.
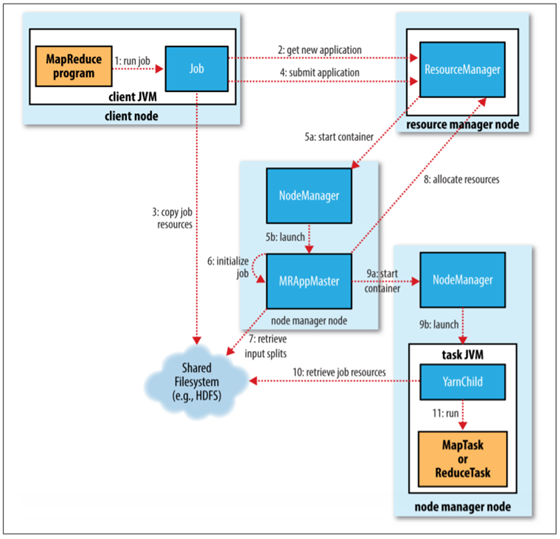
- Job Submission:
The job submission process implemented by JobSubmitter does the following:
- Asks the resource manager for a new application ID, used for the MapReduce job ID (step 2).
- Checks the output specification of the job. For example, if the output directory has not been specified or it already exists, the job is not submitted, and an error is thrown to the MapReduce program.
- Computes the input splits for the job. If the splits cannot be computed (because the input paths don’t exist, for example), the job is not submitted, and an error is thrown to the MapReduce program.
- Copies the resources needed to run the job, including the job JAR file, the configuration file, and the computed input splits, to the shared filesystem in a directory named after the job ID (step 3). The job JAR is copied with a high replication factor so that there are lots of copies across the cluster for the node managers to access when they run tasks for the job.
- Submits the job by calling submitApplication() on the resource manager (step 4).
2. Job Initialization:
- When the resource manager receives a call to its submitApplication() method, it hands off the request to the YARN scheduler. The scheduler allocates a container, and the resource manager then launches the application master’s process.
- The application master for MapReduce jobs is a Java application, it initializes the job by creating a number of bookkeeping objects to keep track of the job’s progress, as it will receive progress and completion reports from the tasks (step 6).
- Next, it retrieves the input splits computed in the client from the shared filesystem (step 7). It then creates a map task object for each split, as well as a number of reduce task. Tasks are given IDs at this point.
To know more about Ids check out my article on Understanding different ID’s that are generated during the Map Reduce Application.
- The application master must decide how to run the tasks that make up the MapReduce job. If the job is small, the application master may choose to run the tasks in the same JVM as itself. Such a job is said to be uberized or run as an uber task.
3. Task Assignment:
- If the job does not qualify for running as an uber task, then the application master requests containers for all the map and reduce tasks in the job from the resource manager (step 8).
- Requests for map tasks are made first and with a higher priority than those for reduce tasks, since all the map tasks must complete before the sort phase of the reduce can start. Requests for reduce tasks are not made until 5% of map tasks have completed.
- Reduce tasks can run anywhere in the cluster, but requests for map tasks have data locality constraints that the scheduler tries to honor.
- In the optimal case, the task is data local that is, running on the same node that the split resides on. Alternatively, the task may be rack local: on the same rack, but not the same node, as the split. Some tasks are neither data local nor rack local and retrieve their data from a different rack than the one they are running on.
- Requests also specify memory requirements and CPUs for tasks. By default, each map and reduce task is allocated 1,024 MB of memory and one virtual core.
4. Task Execution:
- Once a task has been assigned resources for a container on a particular node by the resource manager’s scheduler, the application master starts the container by contacting the node manager (steps 9a and 9b).
- The task is executed by a Java application whose main class is YarnChild. Before it can run the task, it localizes the resources that the task needs, including the job configuration and JAR file, and any files from the distributed cache.
- Finally, it runs the map or reduce task (step 11).
5. Job Completion:
- When the application master receives a notification that the last task for a job is complete, it changes the status for the job to “successful”.
- Then, when the Job polls for status, it learns that the job has completed successfully, so it prints a message to tell the user and then returns from the waitForCompletion() method.
- Job statistics and counters are printed to the console at this point. The application master also sends an HTTP job notification if it is configured to do so.
- Finally, on job completion, the application master and the task containers clean up their working state (so intermediate output is deleted). Job information is archived by the job history server to enable later interrogation by users if desired.
To know more about different types of failure in YARN, check out my article on Different types of failures in Hadoop
Hope you like this article, Happy Learning!!!
