Deep dive into YARN Scheduler options
In real world the clusters are busy and the resources are limited, as a result the applications often need to wait to have some of its resources fulfilled. The YARN scheduler takes the responsibility of allocating the resources to applications based on some defined policies. In this article we are going to discuss about the three scheduling options available in YARN.
1. FIFO Scheduler:
In FIFO (FIRST IN FIRST OUT) scheduler, applications are placed in a queue and runs them in the order of submission. This scheduling option is simple understand and doesn’t require any configuration, but it is not suitable for shared clusters. Let us understand with an example.

In the above example, Job 1 is submitted first and it is a long running job with less priority, after sometime Job 2 which is a high priority job is submitted and takes less time than Job 1. But, since the Job 1 is submitted first, all the resources will be allocated to it and Job 2 has to wait until Job 1 is done.
Limitations:
- Jobs are executed based on FIFO principle and ignores the priority value.
- It is not suitable for shared clusters because large applications will use all the resources and other applications has to wait for it turn.
On shared clusters it is better to use the Capacity Scheduler or the Fair Scheduler.
2. Capacity Scheduler:
The Capacity scheduler allows sharing of a Hadoop cluster among the teams within the organization. Whereby each team is allocated a certain capacity of the overall cluster. Queues may be further divided in hierarchical fashion. But within the queue by default applications are scheduled using FIFO scheduling. In Capacity scheduler, a separate dedicated queue allows the small jobs to start as soon as it is submitted.

In the above example there are two queues A and B, When Job 1 is submitted in Queue A the queue is empty and will take all the resources in the queue. When Job 2 is submitted in Queue B then it starts its execution instead of waiting for Job 1 to finish. Thus capacity scheduler ensures that the priority and small jobs are not starved for longer time when compared to that of FIFO scheduler.
A single job doesn’t use more resources than its queue capacity. However, if there is more than one job in the queue and there are idle resources available, then the capacity scheduler may allocate spare resources to jobs in the queue, even if that cause the queue’s capacity to exceed. This behavior is called Queue Elasticity.
Let see with an example like how the queues are created and allocated for capacity scheduling with example.

The above diagram refers to the capacity scheduling XML file. Let us assume that we have a cluster with <100 cores, 1000 GB >. In the above XML we are splitting the cluster into two queues, prod queue with 60% capacity i.e. <60 cores, 600 GB> and non_prod queue with 40% capacity i.e. <40 cores, 400 GB>. The queue non_prod is further divided into two queues dev and test with equal capacity i.e. <20 cores, 200 GB> each.
Earlier, we discussed about the queue elasticity, let us understand that with the above example. In the above XML we see that the non_prod queue maximum capacity is assigned to 60% which means that if the entire 40% of non_prod queue is utilized and if the prod queue is free then 20% of the prod queue can be utilized. If the parameter is not set then the entire cluster will be used by non prod and it might lead to starvation of production applications. In the above example the prod queue which runs high priority jobs is not having any maximum capacity so that it can use all the cluster resources when needed. Suppose if the non_prod queue is utilizing 60% of the cluster and if an application is submitted to the prod queue than the scheduler by default will starve the application instead of preempting the non_prod queue application.
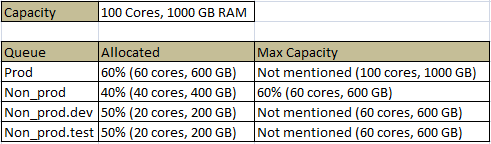
In Capacity scheduler the queue name is identified by the last name. For example it cannot recognize the non_prod_dev but recognizes dev.
Limitations:
- More complex.
- Not easy to configure for everyone.
3. Fair Scheduler:
The Fair scheduler attempts to allocate resources so that all running applications get the same share of resources. The Fair Scheduler is very much similar to that of the capacity scheduler. The priority of the job is kept in consideration. With the help of Fair Scheduler, the YARN applications can share the resources in the large Hadoop Cluster and these resources are maintained dynamically so no need for prior capacity.
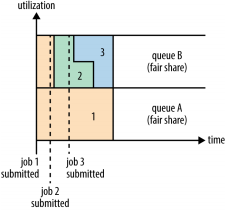
In the above example there are two queues A and B. Job 1 is submitted to Queue A and it is observed that the cluster is empty so Job 1 utilize all the cluster resources. After sometime Job is submitted in Queue B, then the fair share preemption occurs and both the jobs 1 and 2 allocated equal resources in their respective queues. In meanwhile Job 3 is submitted in Queue B and since one job is already running the scheduler will assigned fair share to both thee Jobs in Queue B with equal resources. This way fair scheduler ensures that all the jobs are provided with required resources.
By default the scheduler will be capacity but in real time most of the organizations use the Fair scheduler. Now let us deep dive and understand more about the Fair scheduler.
Let see with an example like how the queues are created and allocated for fair scheduling with example.
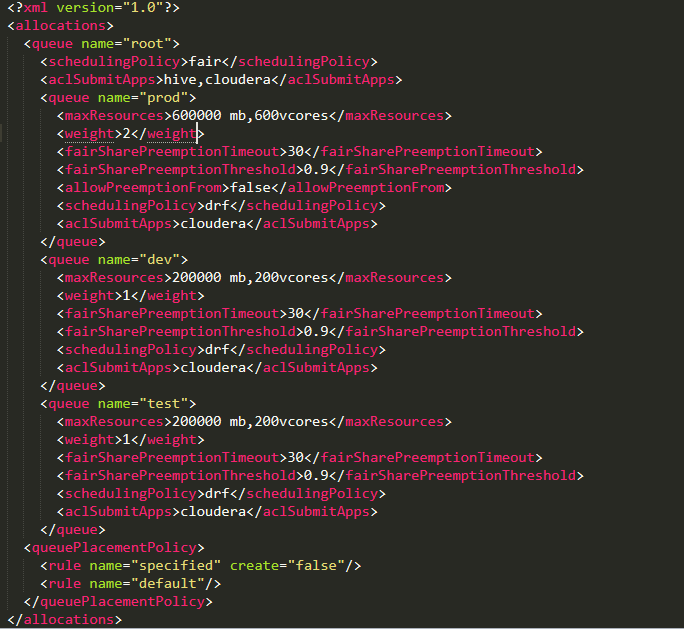
Let us first understand about few parameters used in the above example. The queue hierarchy is defined using nested queue elements. All queues are children of the root queue, even if not actually nested in a root queue element. In the above example we have three queues (prod, dev and test). Queues can have weights, which are used in the fair share calculation. Weights are not quite the same as percentages, even though the example uses numbers that add up to 100 for the sake of simplicity.
Queues can have different scheduling policies. The default policy for queues can be set in the top-level defaultQueueSchedulingPolicy element; if it is omitted, fair scheduling is used. Despite its name, the Fair Scheduler also supports a FIFO policy on queues, as well as Dominant Resource Fairness (drf).
fairSharePreemptionTimeout is number of seconds the queue is under its fair share threshold before it will try to preempt containers to take resources from other queues. If not set, the queue will inherit the value from its parent queue.
fairSharePreemptionThreshold is the fair share preemption threshold for the queue. If the queue waits fairSharePreemptionTimeout without receiving fairSharePreemptionThreshold*fairShare resources, it is allowed to preempt containers to take resources from other queues.
We will now understand the above XML configuration with an example. Let us assume that we have a cluster with 1000 cores and 1000 GB.
Let us calculate the resources that can be assigned to the prod queue.It is noticed that the max resource allocation for prod queue is <600 vcores, 600 GB>. Now let us calculate the fair share that can be assigned to the prod queue.
Steady Fair Share:
The FairScheduler uses hierarchical queues. Queues are sibling queues when they have the same parent. The weight associated with a queue determines the amount of resources a queue deserves in relation to its sibling queues. This amount is known as Steady FairShare.
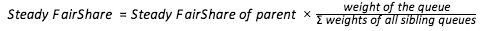
The weight for prod queue is 2, therefore the steady fair share will be 2/4*total cluster resources. i.e<500 cores, 500 GB>.
This number only provides visibility into resources a queue can expect, and is not used in scheduling decisions, including preemption. In other words, it is the theoretical FairShare value of a queue.
Instantaneous Fair Share:
In order to enable queue elasticity in a multi-tenant cluster, FairScheduler allows queues to use more resources than their Steady FairShare when a cluster has idle resources. An active queue is one with at least one running application, whereas an inactive queue is one with no running applications.
Instantaneous FairShare is the calculated FairShare value for each queue based on active queues only. This does not mean that this amount of resources are reserved for this queue.

Suppose if only prod and dev queue are active at a point of time, then instantaneous fair share at that particular point of time will be 2/3*total cluster resources. i.e <666 cores, 667 GB>
This instantaneous fair share changes with time and anything above instantaneous fair share will be preempted as per the preemption conditions.
Similarly we can calculate the steady and instantaneous fair share for dev and test queue. Now let us understand another important parameters related to preemption.
Preemption:
Preemption enables reclamation of resources from queues exceeding their FairShare without waiting for queues to release resources. By default it is set to true for all the queues, we can overwrite it to false if we have some priority queues running in the cluster.
Preemption is enabled when both of the following are true:
- Preemption is enabled at YARN service level via the Enable Fair Scheduler Preemption (
yarn.scheduler.fair.preemption) configuration. Using the preemption timeout mentioned in seconds. - Cluster level resource utilization exceeds the Fair Scheduler Preemption Utilization Threshold (
yarn.scheduler.fair.preemption.cluster-utilization-threshold) which defaults to 80%.
Suppose for prod queue we can see that the fair share preemption timeout is 30 seconds and preemption threshold is 0.9 i.e. 0.9*instantaneous fair share resource capacity. This means for 30 seconds if the queue is having the capacity less than 0.9*instantaneous fair share than preemption will occur.

Dominant Resource Fairness:
Let us now look at the one of the most important scheduling policy i.e. Dominant Resource Fairness a.k.a drf.
When there is only a single resource type being scheduled, such as memory, then the concept of capacity or fairness is easy to determine. If two users are running applications,you can measure the amount of memory that each is using to compare the two applications. However, when there are multiple resource types in play, things get more complicated. If one user’s application requires lots of CPU but little memory and the other’s requires little CPU and lots of memory. how are these two applications compared?
The way that the schedulers in YARN address this problem is to look at each user’s dominant resource and use it as a measure of the cluster usage. This approach is called Dominant Resource Fairness, or DRF for short.
Let us understand this with a simple example, consider a cluster with <18 cores, 36 GB>. Suppose if Job 1 requires <2 cores, 8 GB> and Job requires <6 cores, 2 GB>.
Each Job 1 consumes % of total CPU = 2/18 = 1/9
Each Job 1 consumes % of total RAM = 8/36 = 2/9
Since 2/9 > 1/9 , it is found that Job 1’s dominant resource is RAM.
Similarly,
Each Job 2 consumes % of total CPU = 6/18
Each Job 2 consumes % of total RAM = 2/36 = 1/18
Since 6/18 > 1/18 , it is found that Job 2’s dominant resource is CPU.
For a given job, the %5 of its dominant resource type that it gets cluster-wide is the same for all the jobs. i.e. Job 1’s % of RAM = Job 2’s % of CPU.
It can be written as below linear equation where x is the number of task required for Job 1 and y is the number of tasks required for Job 2.
(2/9)*x = (6/18)*y => (x/y) = (3/2)
Therefore Job 1 get 3 tasks each with <2 cores and 8 GB> and Job 2 gets 2 tasks each with <6 cores and 2 GB>.
This how the resources are allocated in the drf scheduling policy.
Hope you like this article. Happy Learning!!
