HDFS Erasure Coding (EC)
Before we start our discussion on what exactly is Erasure coding, let us understand the below two terms and see how HDFS achieve them.
- Durability: How many simultaneous failure can be tolerated ? It is also known as fault tolerance.
- Storage Efficiency: How much portion of storage is useful for the data in real time?
In HDFS the durability, reliability, read bandwidth and write bandwidth can be achieved by replication process.
To provide fault tolerance, HDFS replicates blocks of a file on different DataNodes depending on the replication factor. So if the default replication factor is 3, then there will be two replicas of the original block.
Suppose if you have a file which can be fit in 3 blocks, by replication factor set to 3 we need to 9 blocks to store the original block and its replicas.

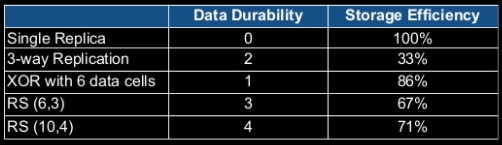
For N-way replication the fault tolerance or durability is N-1 and storage efficiency is 1/N.
Therefore for HDFS replication, the durability is 2 and storage efficiency is 1/3 i.e. 33%. We can clearly see that the storage overhead is almost 200% and very rarely we will be using the second replica. Thus this replication increases the storage overhead and seems to be expensive. Therefore, HDFS uses Erasure Coding in place of replication to provide the same level of fault tolerance with storage overhead to be not more than 50%.
Erasure Coding (EC)
Erasure Coding is introduced in Hadoop 3 and is the solution for the expensive 3x default replication. In Erasure coding the data in the file is divided into smaller units (bit, byte, or block) and stored in consecutive units on different disks(block layout). For each strip of the original dataset, a certain number of parity cells are calculated using Erasure Coding algorithms and these parity cells are stored in disk. This process is called encoding. While reading if their is any error in striping cell that can be recovered from the calculation based on the remaining data and parity cells; the process known as decoding.
Thus using Erasure Coding in HDFS improves storage efficiency while providing the same level of fault tolerance and data durability as traditional replication-based HDFS deployment.
Note: A replication factor of an Erasure Coded file is always one, and we cannot change it.
Block Layouts
Let us first understand the different ways of storing the blocks of data.
- Contiguous Layout
In this layout the data in each block is stored in single datanode in continuous manner. And the parity cells are stored in other datanode based on the continuous strip.

Contiguous layout, is best suitable for achieving the data locality due to the way a single block is stored in one datanode, but for small files this layout is not suitable.
2. Stripped Layout
In this layout, the data in the blocks are divided into small units and these units are stored in sequential manner and parity is calculated based on one strip.

This layout is best suitable for small files but since the data in the blocks are distributed across multiple nodes the data locality is not achieved easily.
Erasure Coding Algorithms
Now we have see the different way the data can be stored across the nodes now let us understand how the parity cells are calculated. There are two Erasure coding algorithms.
1. XOR Algorithm
Its an algorithm based on XOR operation which provides the simplest form of erasure coding. XOR operation is associative and generates 1 parity bit from an arbitrary number of data bits.

In the above example, for the second row the parity cell is 1. If suppose the data of column Y i.e. 1 is lost then using the data of column X and the parity cell we will be able to generate the Y.
XOR algorithm generates only 1 parity bit for any number of data cell inputs, so it can tolerate only 1 failure. Thus it is insufficient for systems like HDFS, which need to handle multiple failures.
The fault tolerance in the XOR algorithm is one, and storage efficiency is 2/3 i.e. 67%.
2. Reed-Solomon Algorithm
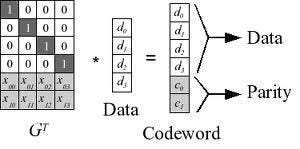
Reed-Solomon Algorithm overcomes the limitation of the XOR algorithm. It uses linear algebra operation to generate multiple parity cells so that it can tolerate multiple failures. RS algorithm multiplies ‘m’ data cells with a Generator Matrix (GT) to get extended codeword with m data cells and n parity cells. If the storage fails, then storage can be recovered by multiplying the inverse of the generator matrix with the extended codewords as long as ‘m’ out of ‘m+n’ cells are available.
The fault tolerance in RS is up to ‘n,’ i.e., the number of parity cells and storage efficiency is m/m+n where m is data cell and n is parity cell.
Advantages of Erasure Coding
- Saving Storage: Initially, blocks are triplicated when they are no longer changed by any additional data, after this, a background task encode it into codeword and delete its replicas.
- Two-way Recovery: HDFS block errors are discovered and recovered not only during reading the path but also we can check it actively in the background.
- Low overhead: Overhead is reduced from 200% to just 50% in RS encoding algorithm.
Limitations of Erasure Coding
- Erasure coding puts additional demands on the cluster in terms of CPU and network.
- Erasure coding adds additional overhead in the reconstruction of the data due to performing remote reads.
- Erasure coding will be mostly used for warm storage data ( Fixed Data ), if the data is changing frequently we need to recalculate the parity each time.
Due to above limitations most of the organization which works on hot data will go with the replication mechanism as it is easy when compared to that of erasure coding. Erasure coding is mainly used by the applications or the organizations which works on cold data.
Hope you like this article. Happy Learning!!
