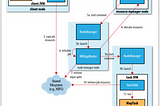
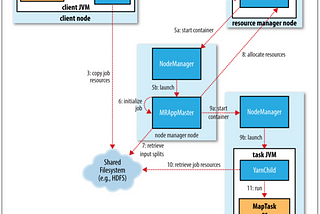
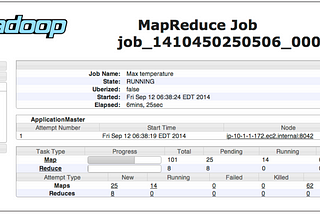
Karthik SharmaDifferent types of failures in HadoopOne of the major advantage of using Hadoop is its ability to handle failures and allow jobs to complete successfully. In this article we…6 min read·Jun 15, 2021----
Karthik SharmaUnderstanding different ID’s that are generated during the Map Reduce Application.In Hadoop 2, Map Reduce jobs are executed using the YARN(Yet Another Resource Negotiator). Let us understand the different id’s that are…2 min read·Jun 10, 2021----
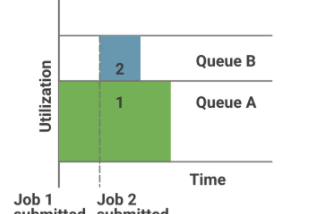
Karthik SharmaDeep dive into YARN Scheduler optionsIn real world the clusters are busy and the resources are limited, as a result the applications often need to wait to have some of its…9 min read·Jun 9, 2021----
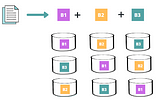
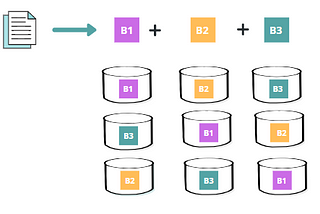
Karthik SharmaHDFS Erasure Coding (EC)Before we start our discussion on what exactly is Erasure coding, let us understand the below two terms and see how HDFS achieve them.5 min read·Jun 4, 2021----
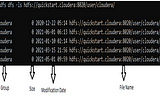
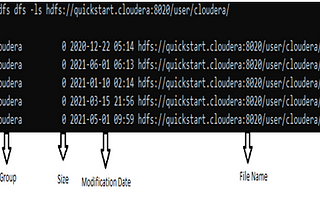
Karthik SharmaUnderstanding HDFS commands with examplesHadoop Distributed File System (HDFS) is file system of Hadoop designed for storing very large files running on clusters of commodity…9 min read·Jun 1, 2021----
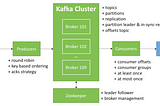
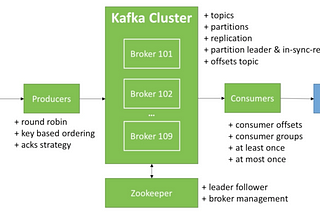
Karthik SharmaIntegrating Kafka with PySparkIn this blog we are going to discuss about how to integrate Apache Kafka with Spark using Python and its required configuration.5 min read·Jan 16, 2021--2--2
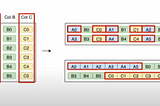
Karthik SharmaUnderstanding Parquet and its Optimization opportunitiesIntroduction to Parquet6 min read·Dec 10, 2020--1--1